Azure Machine Learning Studioで使って理解を深めるResponsible AI (Part 2) – Fairlearn<公平性>編 – #Azure #AzureMachineLearning

こんにちは、Mr.Moです。
前回はMicrosoftのResponsible MLの全体像など、広く浅く触れていきましたが本エントリーでは機械学習モデルの公平性について少し掘り下げて見ていこうと思います。
Fairlearnとは

Fairlearnは、データサイエンティストがAIシステムの公平性を向上させるための、オープンソースでコミュニティ主導のプロジェクトです。AIシステムは、さまざまな理由で不公平な行動をとることがあります。社会的なバイアスが学習データやシステムの開発・展開時の意思決定に反映されていることが原因の場合もあります。また、社会的な偏見ではなく、データの特性(例えば、あるグループの人々に関するデータポイントが少なすぎる)やシステム自体の特性によって、AIシステムが不公平な行動をとる場合もあります。特に、これらの理由は相互に排他的ではなく、互いに悪化させることも多いため、区別するのは難しいでしょう。そのため、AIシステムが不公平な振る舞いをしているかどうかは、人々への影響、つまり害の観点から定義し、社会的な偏りなどの特定の原因や、偏見などの意図の観点からは定義しません。
AI/MLは我々の生活を非常に便利にしていく反面、その影響範囲もかなり広いものになっています。実社会では様々な背景を持った人がいますし、社会の仕組みも複雑です。ですので、本当に望ましい結果をAI/ML導入の先に得るためには、より公平で包括的な機械学習モデルが求められるんですね。(これまでAI/MLを導入した結果、全く問題が発生しなかったとはならなかったためです。それだけ重要な役割にAI/MLが活用されてきていると言えるのかもしれません。)
Fairlearnは機械学習モデルにおいて、その公平性を評価するオープンソースのツールキットです。
Fairlearnによる公平性の評価と軽減の機能
Fairlearnでは、モデルの予測がさまざまなグループ(性別など)にどのように影響するかの評価をダッシュボードを出力することで確認することができます。また、特定のグループにおいて不公平な動作が見られた場合、軽減を行うアルゴリズムを提供します。
ちなみに今回のモデルは、一定の収入以上の方を予測するというモデルです。 まずは実際の画面を見て理解を深めていきましょう。
パフォーマンス、予測の不一致・可視化

上の図はこのモデルのパフォーマンスが可視化された結果です。Oveerall(全体の精度)が85%でさらに性別ごとの精度でも見ているところです。女性が92.6%、男性が81.1%ですね差は18.2%ほどあります。さらに下のオレンジと青色のグラフを見ていくと、予測を外した(エラー)の結果が見えていいますね。オレンジの部分は『予測』は一定の収入以下(0)と出したが、『実際』は一定の収入以上(1)であった結果で過小評価と言えるものになります。青色の部分は『予測』は一定の収入以上(1)と出したが、『実際』は一定の収入以下(0)であった結果で過大評価と言えるものです。こうしてみるとこのモデルは女性をやや過小評価し、男性をやや過大評価するという予測動作をすると見ることができます。(さらに他の例でいうと、例えばエンジニアの採用を決定するモデルがあった時に、男性を採用しやすい予測動作をするモデルも同じような傾向の評価結果がでると思いますが、はたして男性というだけでエンジニアの素質があるとして良いのかということです。この例でいうとエンジニアの素質に性別は関係無いので、性別という特定のグループにおいて現実に沿わない不公平な予測動作が潜んでいるということになります。)
選択率・可視化

次に上の図の選択率というところを見ていきます。これは全体の人数のうち一定の収入以上とされた方の割合をあわらしています。Oveerall(全体)では20.6%であり、女性だけだと8.45%、男性は26.7%となっていますね。このモデルにおいて、男女間で差が生まれてしまっています。では、ここからどのように対応すれば良いのでしょうか?
不公平性の軽減と複数のモデルの比較


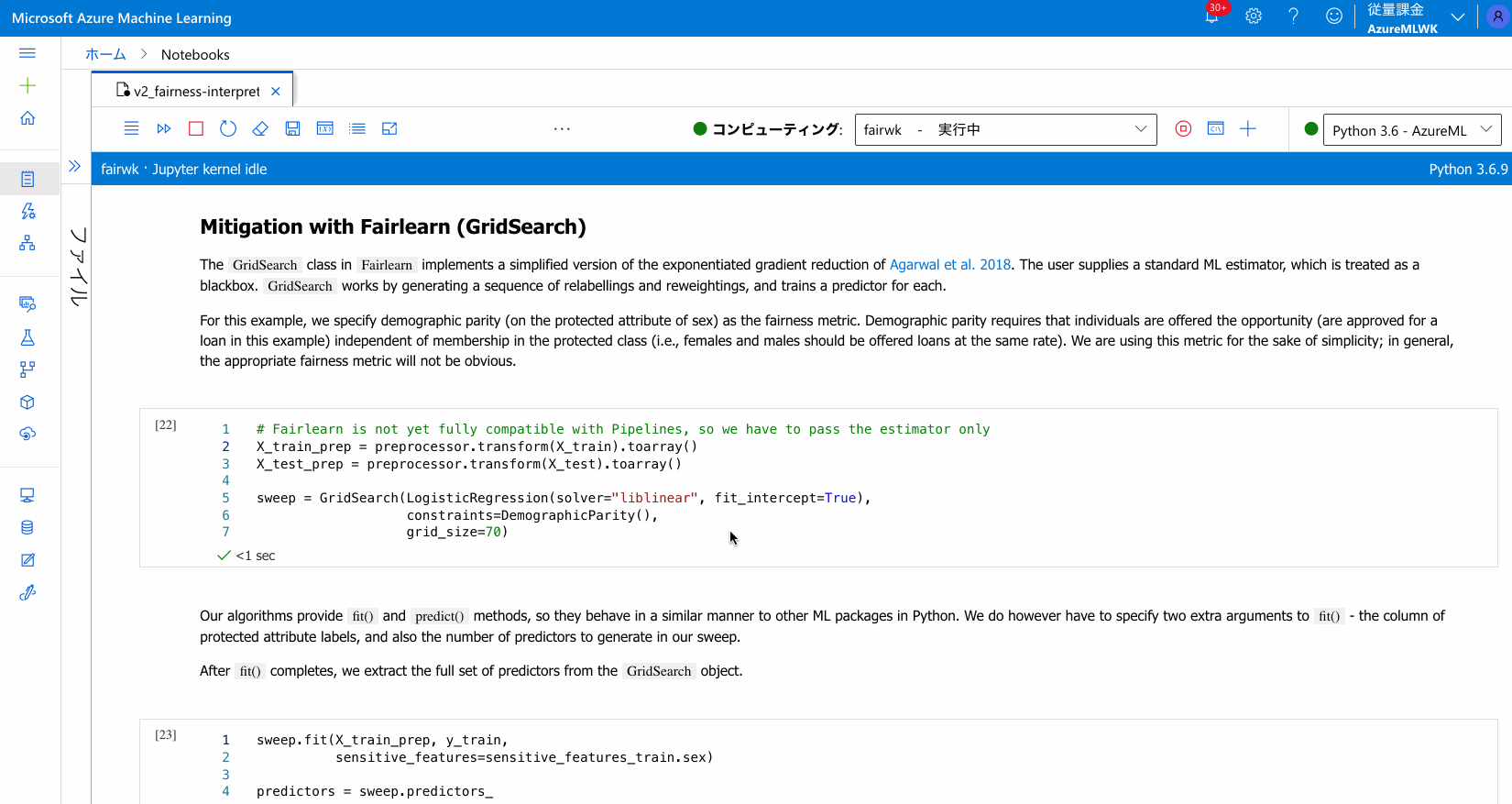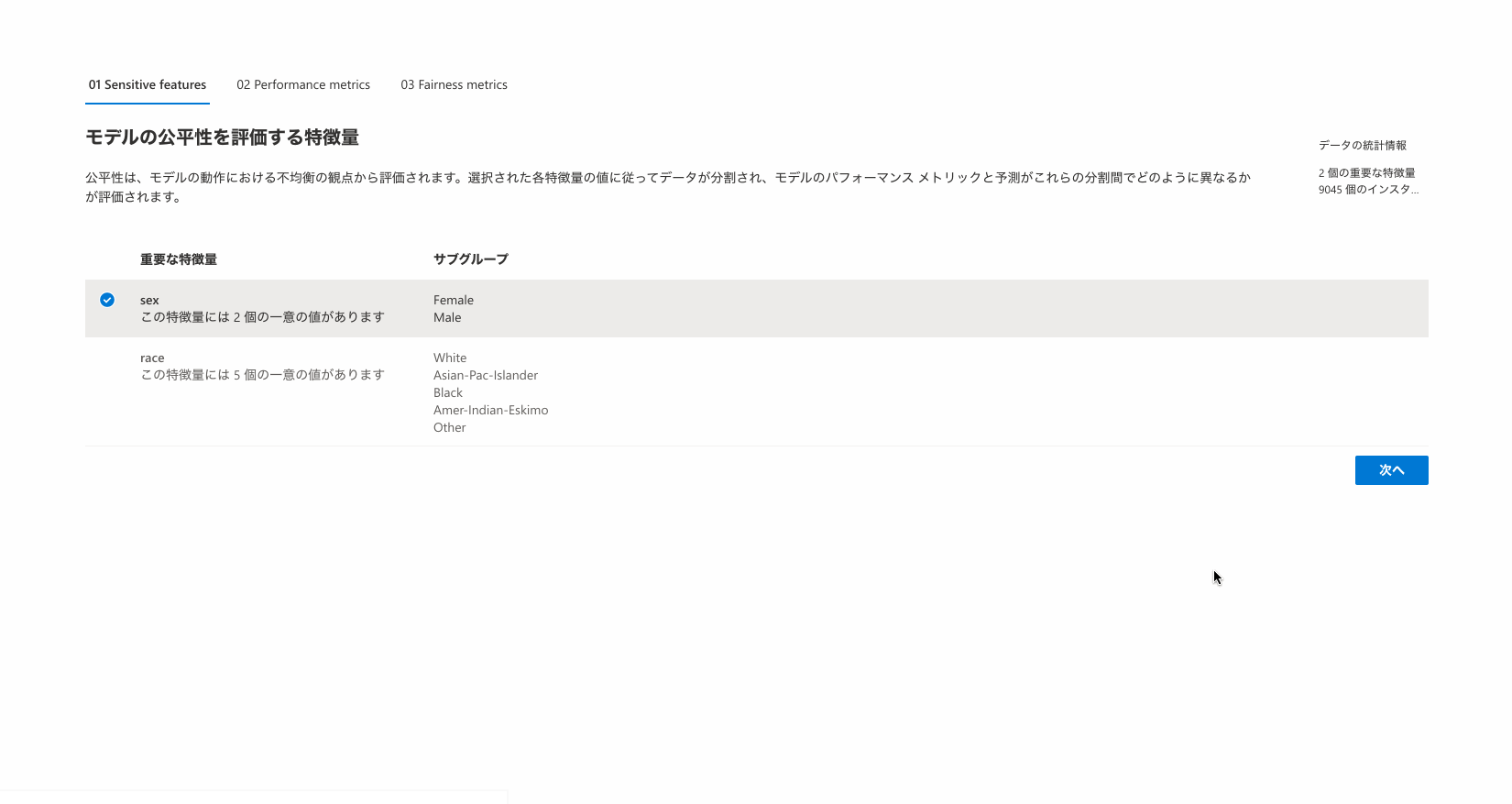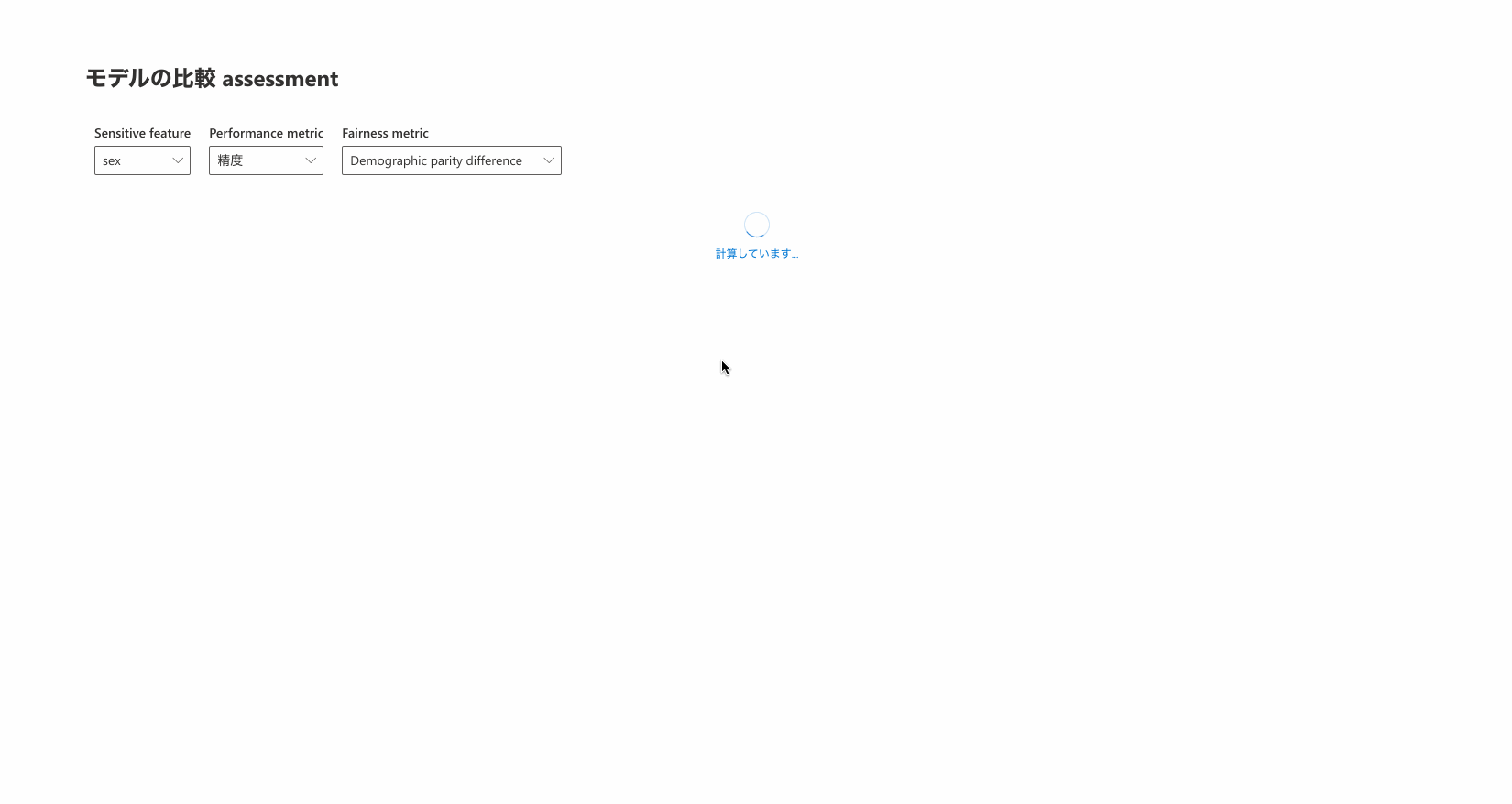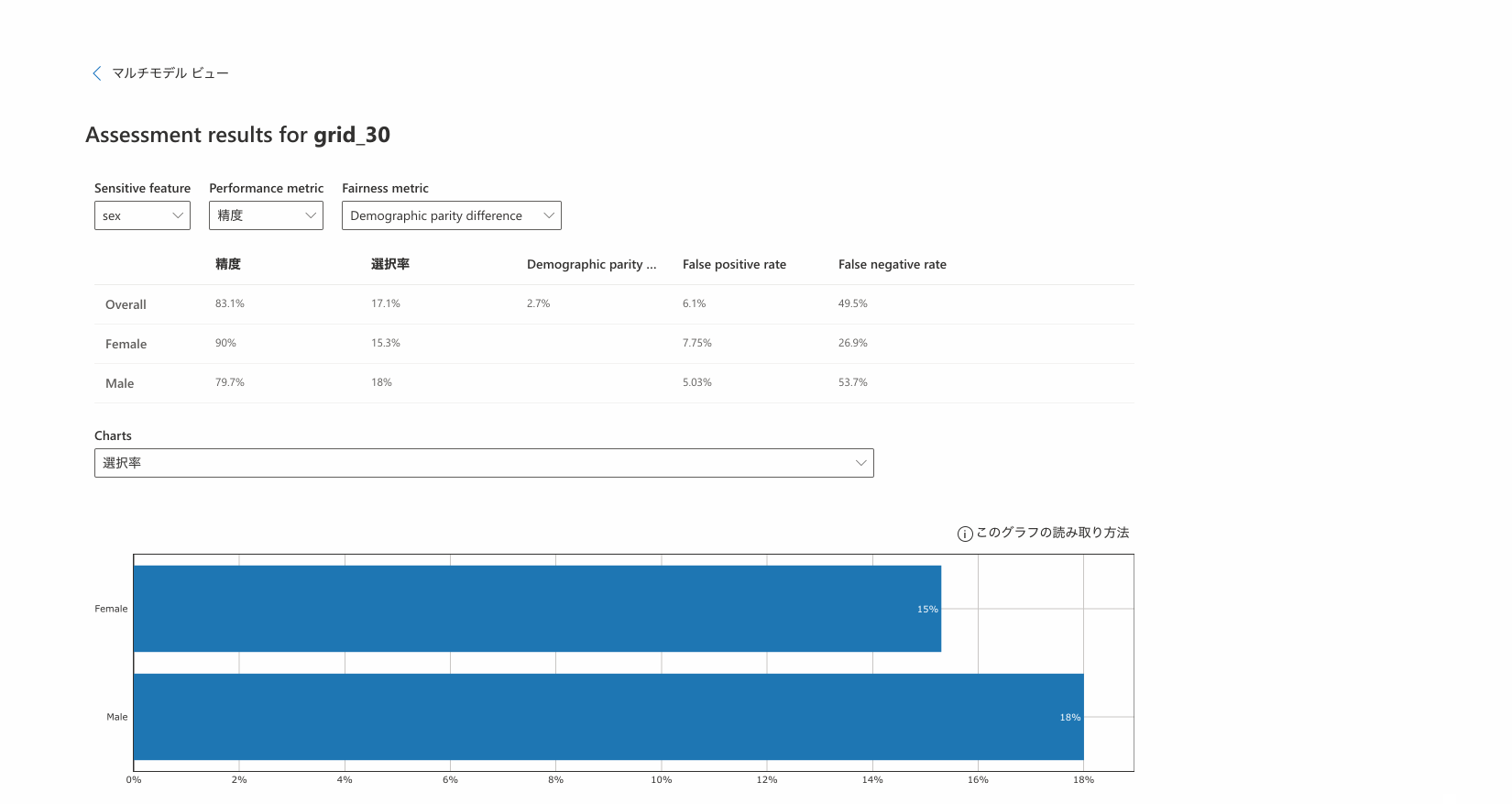
Fairlearnではこのような不公平な差を軽減するアルゴリズムが用意されています。上の図は軽減アルゴリズムを使用して再トレーニングされたモデルが表示されているところです。この図のように開発者はパフォーマンスと公平性の適切なトレードオフのモデルを選択することが可能なわけです。先ほどはOveerall(全体の精度)が85%のモデルでしたので、今度はOveerall(全体の精度)が83.1%と精度を保ちつつ男女間の不公平性をグッと抑えたモデルを選択しています。すると下の図のように男女間の差が小さい結果が出ていますね!
実際に使っているところ&コードを見てみる
それではコードを抜粋して見ていきましょう。ちなみに参考にしたサンプルコードはコチラになります。実行環境はAzure Machine Learning StudioのNotebooksを使用しています、使い方などはコチラのエントリーを参考にしてみてください。
まず下記のように関心のある特徴量(ここだとsexとrace)を選択することから始めます。あとはだいぶ省略しますが、通常通りのモデルの構築を行い、Fairlearnのライブラリに必要な情報を渡していくという流れです。
## 関心のある特徴量を取得
sensitive_features = X_raw[['sex','race']]
X_train, X_test, y_train, y_test, sensitive_features_train, sensitive_features_test = \
train_test_split(X_raw, y, sensitive_features,
test_size = 0.2, random_state=0, stratify=y)
## Fairlearnのライブラリを使用し、必要な情報を渡しているところ。ダッシュボードが出力される
from raiwidgets import FairnessDashboard
FairnessDashboard(sensitive_features=sensitive_features_test,
y_true=y_test,
y_pred=y_pred)
するとダッシュボードが出力されて、先ほど説明したような情報を見ることができます。

また、FairlearnはAzure Machine Learningに統合することができるので、下記のコードはそちらを実施しているところです。
exp = Experiment(ws, "Responsbile_ML_Demo")
print(exp)
run = exp.start_logging()
# Upload the dashboard to Azure Machine Learning
try:
dashboard_title = "Fairness insights of Logistic Regression Classifier"
# Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s)
upload_id = upload_dashboard_dictionary(run,
dash_dict,
dashboard_name=dashboard_title)
print("\nUploaded to id: {0}\n".format(upload_id))
# To test the dashboard, you can download it back and ensure it contains the right information
downloaded_dict = download_dashboard_by_upload_id(run, upload_id)
finally:
run.complete()
下記のようにAzure Machine Learningの実験から確認できていますね。まだプレビューの機能ではありますが過去の結果と比較などできるのは大変嬉しいですね。

そして下記が不公平性の軽減アルゴリズムを使用しているコードです。再トレーニングを行い、ダッシュボードを出力しています。
## Fairlearnのライブラリが提供する不公平性の軽減アルゴリズムを使用しているところ
## constraintsにはサポートされている制約を指定している
## https://fairlearn.org/v0.6.0/user_guide/mitigation.html#demographic-parity
from fairlearn.reductions import GridSearch
sweep = GridSearch(LogisticRegression(solver="liblinear", fit_intercept=True),
constraints=DemographicParity(),
grid_size=70)
## 再トレーニング
sweep.fit(X_train_prep, y_train,
sensitive_features=sensitive_features_train.sex)
predictors = sweep.predictors_
## Fairlearnのライブラリを使用し、必要な情報を渡しているところ。ダッシュボードが出力される
dominant_all = {}
for name, predictor in dominant_models_dict.items():
dominant_all[name] = predictor.predict(X_test_prep)
FairnessDashboard(sensitive_features=sensitive_features_test,
y_true=y_test,
y_pred=dominant_all)
いちおう、コードの全文はコチラにおきました。
まとめ
このように既存のモデル構築処理の流れに組み込めるようになっているのは導入しやすくて良いですね。また、Azure Machine Learningと組み合わせて使うとトレーニングの用のパワフルなコンピュータリソースも使えますし、Fairlearnといった機能が統合されていっている動向もあるので、やはり効率の良い環境と言えそうです。
今回見たFairlearnの機能はほんの一部にすぎませんが、皆さんの方でもこういった機能の重要性、およびモデルの理解・把握に対する可能性が見えたのではないでしょうか。
また、もっと色々知りたい方はぜひ公式のドキュメントなどをご覧いただければと思います!
- https://fairlearn.org/v0.6.0/user_guide/fairness_in_machine_learning.html
- https://docs.microsoft.com/ja-jp/azure/machine-learning/concept-fairness-ml
次回はError Analysisを見ていきます。

